CUDA расшифровывается как Compute Unified Device Architecture, что в переводе гласит: "Архитектура устройств с поддержкой универсальных вычислений". Эти устройства ни что иное, как видеокарты производства NVidia. Таких видеокарт с поддержкой CUDA выпущено очень много, как в дорогом, так и в дешёвом исполнении. Разумное использование технологии позволит получить неплохую производительность, но не всё так просто...
Аппаратная платформа
На сегодняшний день видеокарты являются мини-компьютерами в компьютере. На одной плате расположены вычислительные модули, память, контроллеры и др. В карточке мы имеем входной поток данных, состоящий из однородных элементов, обрабатываемых одной инструкцией. Каждый поток независим от себя, что позволяет нам запараллелить процесс.Общая задача - обработка входного потока данных - делится на множество мелких подзадач, каждая из которых обрабатывается своей нитью.
Нити же исполняются параллельно на вычислительных модулях, в качестве которых используется набор потоковых мультипроцессоров.
SIMT - single instruction, multiple threads
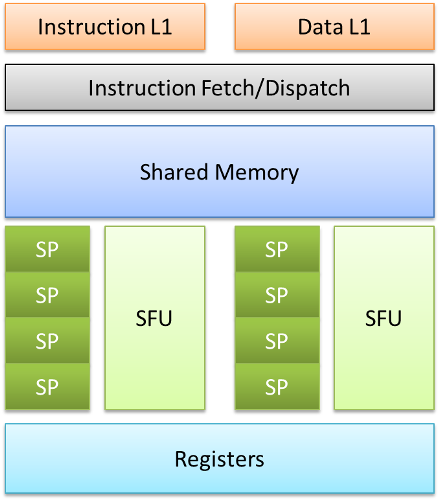
Основа здесь - это SP - потоковые процессоры (streaming processor), или CUDA-процессоры. Именно они выполняют инструкции по обработке данных. Мультиплексор включает в себя 8 таких блоков, так же имеются два SFU блока, используемых для сложных вычислений, например - тригонометрических. Далее, в состав SM входит набор регистров (на схеме - Registers). Их количество в SM архитектуры Tesla 8 равно 8192, разрядность каждого из них - 32 бита. Кроме того, SM содержит ещё и общую для всех CUDA-ядер память (Shared Memory), суммарным объёмом 16 Кбайт.
Фактически, и блок регистров, и общая память - наиболее близкая к потоковому процессору единица памяти, взаимодействие с ней очень быстрое, значительно быстрее, чем с DRAM - модулями памяти, рассеянными на плате.
Главное отличие между регистровой и разделяемой памятью в том, что регистры распределяются на этапе компиляции, и во время выполнения строго разграничены между потоками, выполняющимися на CUDA-ядрах, т.е. их распределением управляет компилятор. В то время как Shared Memory могут использовать все нити выполнения программы, и эта память доступна программисту посредством ключевого слова shared.
Потоковые мультиплексоры
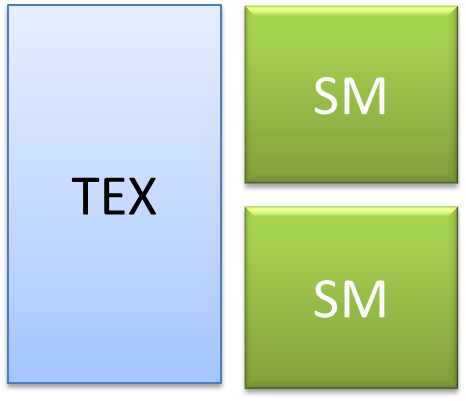
Здесь TEX - это блок доступа к текстурам. Видно, что один блок обработки текстур содержит 2 мультипроцессора. Это относится к архитектуре Tesla 8, у более поздней продукции схема немного иная. TPC - наиболее крупная структурная единица. Шейдерный блок видеокарты состоит из набора таких вот модулей и набора различных вспомогательных схем служащих, например, для организации доступа к DRAM. Благодаря этому имеется операция двойной точности, но это слишком дорого, требует большого количества ресурсов и по-этому используется немного иной вид мультиплексора, а именно с использованием 3 мультиплексоров:

Вот то, что примерно творится внутри CUDA-совместимых карточек.
Итак, краткие выводы:
- CUDA использует принцип SIMT;
- нити выполняются на потоковых процессорах;
- потоковые процессоры размещаются в потоковых мультипроцессорах;
- мультипроцессор содержит различного вида память, планировщик нитей, модули специальных функций;
- вычислительная мощность прямо пропорциональна числу мультипроцессоров;
- с CUDA совместимо огромное число видеоадаптеров, начиная от GeForce 8300 и заканчивая GeForce GTX480.