Мы попробуем создать ядро, передать ему набор параметров и получить результат.
Первые шаги аналогичны предыдущему примеру.
- Создадим проект
- Создадим ссылку на CUDA.NET
1 Создание ядра
Создадим файл mykernel.cu и добавим его в состав нашего проекта.
2 Объявление
В этом файле объявим функцию-ядро:
extern "C" __global__ void test_func(int *g_data, int inc_value)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
g_data[idx] = g_data[idx] + inc_value;
}
Ключевое слово _global_ означает, что функция является ядром. Наше ядро принимает набор параметров - массив в виде указателя на целое и велечину инкремента. test_func будет увеличивать каждый элемент массива на заданную величину.{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
g_data[idx] = g_data[idx] + inc_value;
}
В первой строке тела функции мы вычисляем индекс текущего обрабатываемого элемента. Делается это так: исходная задача (grid) делится на определённое число блоков заданного размера. Блоки располагаются последовательно по цепочке. Значит, чтобы найти индекс очередного обрабатываемого элемента, достаточно индекс текущего блока (blockIdx) умножить на его размер (blockDim) и прибавить индекс текущей нити (threadIdx). Поскольку нити в блоке и грид блоков одномерные, используется только X-индексы. После этого во второй строке увеличиваем элемент массива на значение переданного аргумента.
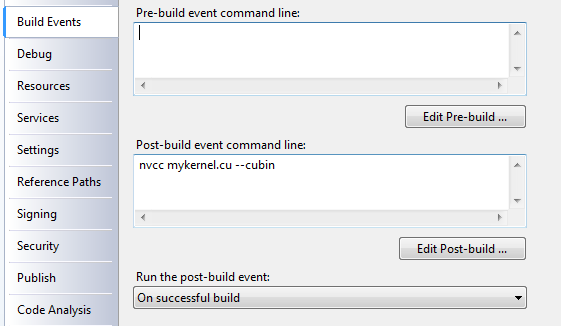
Полученный *.cu файл нужно скомпилировать при помощи nvcc. Для этого в свойствах проекта в Post-build actions указываем следующую командную строку:
----------------
PS: Небольшой совет для пользователей 64-разрядных версий Windows: после установки CUDA Toolkit и SDK компиляция *.cu файлов может не проходить успешно, с сообщением "Cannot open include file: 'crtdefs.h': No such file or directory". Это легко исправить модификацией файла nvcc.profile, расположенный умолчанию по такому пути: C:\CUDA\bin64\nvcc.profile. Нужно поменять значение INCLUDE на следующее:
INCLUDES += "-I$(TOP)/include" "-I$(TOP)/include/cudart" "-IC:/Program Files (x86)/Microsoft Visual Studio 9.0/VC/include" $(_SPACE_)
Все изменения сводятся к добавлению ещё одного пути, где nvcc будет искать заголовочные файлы. Собственно решение найдено на форуме NVidia.
----------------
3 Хост-приложение
Инициализируем драйвер видеокарты и исходный массив:
CUDA cuda = new CUDA( 0, true );
Int32[] array = Enumerable.Range( 0, 4096 ).ToArray();
Int32[] array = Enumerable.Range( 0, 4096 ).ToArray();
Устройство под номером 0 - это первая и единственная видеокарта в моей системе. Входной массив содержит 4096 элементов - от 0 до 4095. Скопируем его в память видеоадаптера:
CUdeviceptr d_input = cuda.CopyHostToDevice<Int32>( array );
cuda.LoadModule( "mykernel.cubin" );
Получаем дескриптор нашей функции:
CUfunction func = cuda.GetModuleFunction( "test_func" );
Указываем параметры запуска:
cuda.SetFunctionBlockShape( func, 512, 1, 1 );
cuda.SetParameter( func, 0, ( uint )d_input.Pointer );
cuda.SetParameter( func, IntPtr.Size, ( uint )42 );
cuda.SetParameterSize( func, ( uint )( IntPtr.Size + sizeof( uint ) ) );
cuda.SetParameter( func, 0, ( uint )d_input.Pointer );
cuda.SetParameter( func, IntPtr.Size, ( uint )42 );
cuda.SetParameterSize( func, ( uint )( IntPtr.Size + sizeof( uint ) ) );
Для начала определим размер блока - пусть это будет совокупность из 512 нитей - т.е. обработка входной последовательности будет производиться блоками по 512 элементов. Делается это при помощи вызова SetFunctionBlockShape, блоки будут одномерными, поэтому y- и z-размерности устанавливаем в 1. Далее передадим параметры нашей функции. Для этого передаём указатель на скопированный в DRAM GPU массив при помощи SetParameter, и тем же способом задаём приращение (пусть это будет 42). В конце следует указать общий размер параметров функции при помощи вызова SetParameterSize.
Запускаем функцию на исполнение и копируем результат обратно в память хоста:
cuda.Launch( func, array.Length / 512, 1 );
cuda.CopyDeviceToHost<int>( d_input, array );
cuda.CopyDeviceToHost<int>( d_input, array );
При вызове метода Launch определим размеры грида. В нашем случае удобно сделать одномерный грид - фактически, просто цепочку блоков заданного размера. Параметры блока мы задали ранее, размер его - 512 нитей. Значит, размер грида будет равна числу частному от деления числа элементов во входном массиве (array.Length) на размер блока (512). Грид одномерный, поэтому y-размер его равен 1. Стоит отметить, что данный вызов метода является синхронным. Т.е. возврат из метода не будет произведён, пока наше ядро не обработает все элемента массива. Впрочем, библиотека CUDA.NET позволяет производить вызовы в асинхронном режиме. После того как функция-ядро успешно отработает, можно забрать результаты с устройства - сделаем это посредством вызова CopyDeviceToHost - скопируем результаты в тот же массив, который содержал исходные данные.
Освободим ранее выделенную память (метод Free) и выведем на экран результат:
cuda.Free( d_input );
foreach ( var item in array )
{
Console.WriteLine( item );
}
foreach ( var item in array )
{
Console.WriteLine( item );
}
На этом всё! В результате ожидается увидеть на консоли ряд целых чисел от 0 до 4095, увеличенные на 42.